How Cloudflare Workers Minimize Latency
Cloudflare Workers operate on a serverless architecture running on Cloudflare’s global edge network. This means your requests are processed at the edge, reducing the distance data has to travel and significantly lowering latency. Workers are powered by V8 isolates, which are lightweight and have extremely fast startup times. This eliminates cold starts and ensures quick response times for your applications.Benchmarking Helicone’s Proxy Service
To demonstrate the negligible latency introduced by Helicone’s proxy, we conducted the following experiment:- We interleaved 500 requests with unique prompts to both OpenAI and Helicone.
- Both received the same requests within the same 1-second window, varying which endpoint was called first for each request.
- We maximized the prompt context window to make these requests as large as possible.
- We used the
text-ada-001model. - We logged the roundtrip latency for both sets of requests.
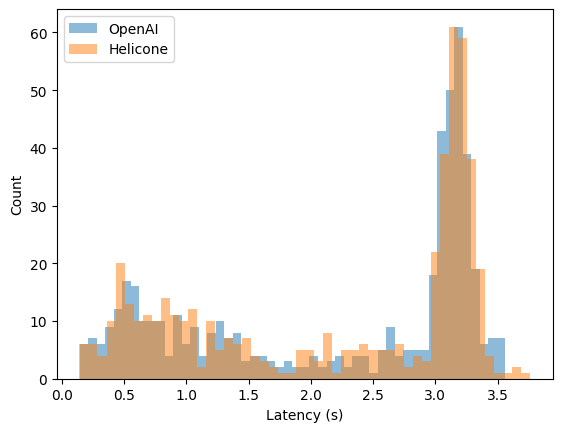
Results
The metrics show that Helicone’s latency closely matches that of direct requests to OpenAI. The slight differences at the right tail indicate a minimal overhead introduced by Helicone, which is negligible in most practical applications. This demonstrates that using Helicone’s proxy does not significantly impact the performance of your LLM requests.
FAQ
Need more help?
Need more help?
Additional questions or feedback? Reach out to
help@helicone.ai or schedule a
call with us.