> ## Documentation Index
> Fetch the complete documentation index at: https://docs.helicone.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Platform Overview
> Understand how Helicone solves the core challenges of building production LLM applications
Now that your requests are flowing through Helicone, let's explore what you can do with the platform.
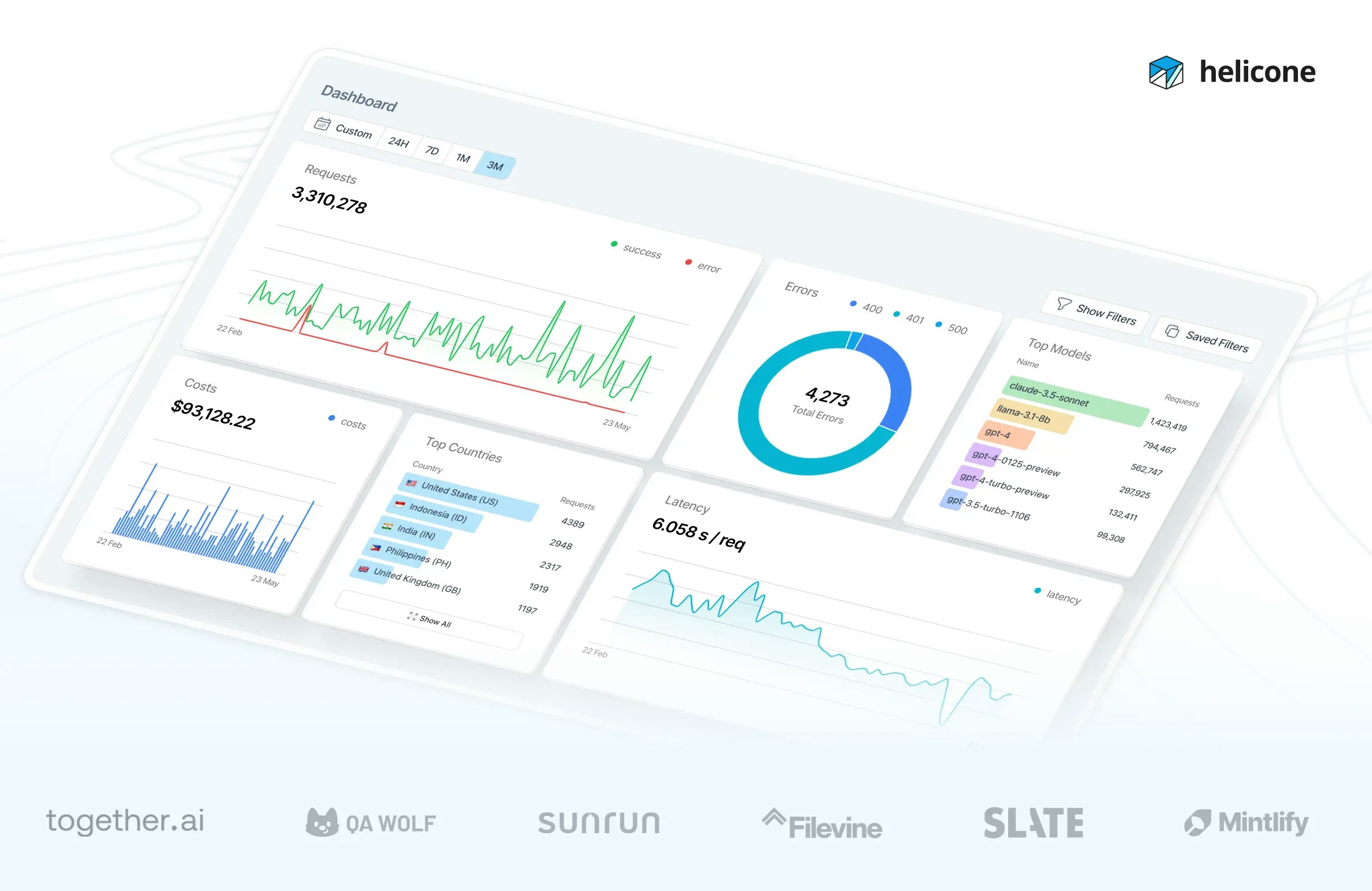 ## What is Helicone?
We built Helicone to solve the hardest problems in production LLM applications: provider outages that break your app, unpredictable costs, and debugging issues that are impossible to reproduce. Our platform combines observability with intelligent routing to give you complete visibility and reliability.
In short: **monitor everything, route intelligently, never go down.**
## The Problems We Solve
Provider outages break your application. No visibility when requests fail. Manual fallback logic is complex and error-prone.
LLM responses are non-deterministic. Multi-step AI workflows are hard to trace. Errors are difficult to reproduce.
Unpredictable spending across providers. No understanding of unit economics. Difficult to optimize without breaking functionality.
Every prompt change requires a deployment. No version control for prompts. Can't iterate quickly based on user feedback.
## How It Works
Helicone works in two ways: use our **AI Gateway** with pass-through billing (easiest), or bring your own API keys for observability-only mode.
### Option 1: AI Gateway (Recommended)
Access 100+ LLM models through a single unified API with zero markup:
1. **Add Credits** - Top up your Helicone account (0% markup)
2. **Single Integration** - Point your OpenAI SDK to our gateway URL
3. **Use Any Model** - Switch between providers by just changing the model name
4. **Automatic Observability** - Every request is logged with costs, latency, and errors tracked
Credits let you access 100+ LLM providers without signing up for each one. Add funds to your Helicone account and we manage all the provider API keys for you. You pay exactly what providers charge (0% markup) and avoid provider rate limits. [Learn more about credits](https://helicone.ai/credits).
No need to sign up for OpenAI, Anthropic, Google, or any other provider. We manage the API keys and you get complete observability built in.
Prefer to use your own API keys? You can configure your own provider keys at [Provider Keys](https://us.helicone.ai/providers) for direct control over billing and provider accounts. You'll still get full observability, but you'll manage provider relationships directly.
## Our Principles
**Best Price Always**
We fight for every penny. 0% markup on credits means you pay exactly what providers charge. No hidden fees, no games.
**Invisible Performance**\
Your app shouldn't slow down for observability. Edge deployment keeps us under 50ms. Always.
**Always Online**\
Your app stays up, period. Providers fail, we fallback. Rate limits hit, we load balance. We don't go down.
**Never Be Surprised**\
No shock bills. No mystery spikes. See every cost as it happens. We believe in radical transparency.
**Find Anything**\
Every request, searchable. Every error, findable. That needle in the haystack? We'll help you find it.
**Built for Your Worst Day**\
When production breaks and everyone's panicking, we're rock solid. Built for when you need us most.
## Real Scenarios
**What happened:** Your AWS bill shows \$15K in LLM costs this month vs \$5K last month.
**How Helicone helps:**
* Instant breakdown by user, feature, or any custom dimension
* See exactly which user/feature caused the spike
* Take targeted action in minutes, not days
**Real example:** An enterprise customer had an API key leaked and racked up over \$1M in LLM spend. With Helicone's user tracking and custom properties, they identified the compromised key within minutes and prevented further damage.
**What happened:** Customer support forwards a complaint that your AI chatbot gave incorrect information.
**How Helicone helps:**
* View the complete conversation history with session tracking
* Trace through multi-step workflows to find where it failed
* Identify the exact prompt that caused the issue
* Deploy the fix instantly with prompt versioning (no code deploy needed)
**Real impact:** Traced bad response to outdated prompt version. Fixed and deployed new version in 5 minutes without engineering.
**What happened:** OpenAI API returns 503 errors. Your production app stops working.
**How Helicone helps:**
* Configure automatic fallback chains (e.g., GPT-4o: OpenAI → Vertex → Bedrock)
* Requests automatically route to backup providers when failures occur
* Users get responses from alternative providers seamlessly
* Full observability maintained throughout the outage
**Real impact:** App stayed online during 2-hour OpenAI outage. Users never noticed.
**What happened:** Your multi-step AI agent isn't completing tasks. Users are frustrated.
**How Helicone helps:**
* Session trees visualize the entire workflow across multiple LLM calls
* Trace exactly where the sequence breaks down
* See if it's hitting token limits, using wrong context, or failing prompt logic
* Pinpoint the root cause in the chain of reasoning
**Real impact:** Discovered agent was hitting context limits on step 3. Adjusted prompt strategy and fixed cascading failures.
## Comparisons
Helicone is unique in offering both AI Gateway and full observability in one platform. Here's how we compare:
| Feature | Helicone | OpenRouter | LangSmith | Langfuse |
| ---------------------- | --------------------- | ----------- | --------- | -------- |
| **Pricing** | 0% markup / \$20/seat | 5.5% markup | \$39/seat | \$59/mo |
| **AI Gateway** | ✅ | ✅ | ❌ | ❌ |
| **Full Observability** | ✅ | ❌ | ✅ | ✅ |
| **Caching** | ✅ | ❌ | ❌ | ❌ |
| **Custom Rate Limits** | ✅ | ❌ | ❌ | ❌ |
| **LLM Security** | ✅ | ❌ | ❌ | ❌ |
| **Session Debugging** | ✅ | ❌ | ✅ | ✅ |
| **Prompt Management** | ✅ | ❌ | ✅ | ✅ |
| **Integration** | Proxy or SDK | Proxy | SDK only | SDK only |
| **Open Source** | ✅ | ❌ | ❌ | ✅ |
See our [OpenRouter migration guide](https://www.helicone.ai/blog/migration-openrouter) for a detailed comparison and step-by-step instructions.
See our [LLM observability platforms guide](https://www.helicone.ai/blog/the-complete-guide-to-LLM-observability-platforms) for an in-depth feature breakdown.
## Start Exploring Features
Use 100+ models through one unified API with automatic fallbacks
Debug complex AI agents and multi-step workflows
Deploy prompts without code changes
Track cost and understand the unit economics of your LLM applications
***
We built Helicone for developers with users depending on them. For the 3am outages. For the surprise bills. For finding that one broken request in millions.
## What is Helicone?
We built Helicone to solve the hardest problems in production LLM applications: provider outages that break your app, unpredictable costs, and debugging issues that are impossible to reproduce. Our platform combines observability with intelligent routing to give you complete visibility and reliability.
In short: **monitor everything, route intelligently, never go down.**
## The Problems We Solve
Provider outages break your application. No visibility when requests fail. Manual fallback logic is complex and error-prone.
LLM responses are non-deterministic. Multi-step AI workflows are hard to trace. Errors are difficult to reproduce.
Unpredictable spending across providers. No understanding of unit economics. Difficult to optimize without breaking functionality.
Every prompt change requires a deployment. No version control for prompts. Can't iterate quickly based on user feedback.
## How It Works
Helicone works in two ways: use our **AI Gateway** with pass-through billing (easiest), or bring your own API keys for observability-only mode.
### Option 1: AI Gateway (Recommended)
Access 100+ LLM models through a single unified API with zero markup:
1. **Add Credits** - Top up your Helicone account (0% markup)
2. **Single Integration** - Point your OpenAI SDK to our gateway URL
3. **Use Any Model** - Switch between providers by just changing the model name
4. **Automatic Observability** - Every request is logged with costs, latency, and errors tracked
Credits let you access 100+ LLM providers without signing up for each one. Add funds to your Helicone account and we manage all the provider API keys for you. You pay exactly what providers charge (0% markup) and avoid provider rate limits. [Learn more about credits](https://helicone.ai/credits).
No need to sign up for OpenAI, Anthropic, Google, or any other provider. We manage the API keys and you get complete observability built in.
Prefer to use your own API keys? You can configure your own provider keys at [Provider Keys](https://us.helicone.ai/providers) for direct control over billing and provider accounts. You'll still get full observability, but you'll manage provider relationships directly.
## Our Principles
**Best Price Always**
We fight for every penny. 0% markup on credits means you pay exactly what providers charge. No hidden fees, no games.
**Invisible Performance**\
Your app shouldn't slow down for observability. Edge deployment keeps us under 50ms. Always.
**Always Online**\
Your app stays up, period. Providers fail, we fallback. Rate limits hit, we load balance. We don't go down.
**Never Be Surprised**\
No shock bills. No mystery spikes. See every cost as it happens. We believe in radical transparency.
**Find Anything**\
Every request, searchable. Every error, findable. That needle in the haystack? We'll help you find it.
**Built for Your Worst Day**\
When production breaks and everyone's panicking, we're rock solid. Built for when you need us most.
## Real Scenarios
**What happened:** Your AWS bill shows \$15K in LLM costs this month vs \$5K last month.
**How Helicone helps:**
* Instant breakdown by user, feature, or any custom dimension
* See exactly which user/feature caused the spike
* Take targeted action in minutes, not days
**Real example:** An enterprise customer had an API key leaked and racked up over \$1M in LLM spend. With Helicone's user tracking and custom properties, they identified the compromised key within minutes and prevented further damage.
**What happened:** Customer support forwards a complaint that your AI chatbot gave incorrect information.
**How Helicone helps:**
* View the complete conversation history with session tracking
* Trace through multi-step workflows to find where it failed
* Identify the exact prompt that caused the issue
* Deploy the fix instantly with prompt versioning (no code deploy needed)
**Real impact:** Traced bad response to outdated prompt version. Fixed and deployed new version in 5 minutes without engineering.
**What happened:** OpenAI API returns 503 errors. Your production app stops working.
**How Helicone helps:**
* Configure automatic fallback chains (e.g., GPT-4o: OpenAI → Vertex → Bedrock)
* Requests automatically route to backup providers when failures occur
* Users get responses from alternative providers seamlessly
* Full observability maintained throughout the outage
**Real impact:** App stayed online during 2-hour OpenAI outage. Users never noticed.
**What happened:** Your multi-step AI agent isn't completing tasks. Users are frustrated.
**How Helicone helps:**
* Session trees visualize the entire workflow across multiple LLM calls
* Trace exactly where the sequence breaks down
* See if it's hitting token limits, using wrong context, or failing prompt logic
* Pinpoint the root cause in the chain of reasoning
**Real impact:** Discovered agent was hitting context limits on step 3. Adjusted prompt strategy and fixed cascading failures.
## Comparisons
Helicone is unique in offering both AI Gateway and full observability in one platform. Here's how we compare:
| Feature | Helicone | OpenRouter | LangSmith | Langfuse |
| ---------------------- | --------------------- | ----------- | --------- | -------- |
| **Pricing** | 0% markup / \$20/seat | 5.5% markup | \$39/seat | \$59/mo |
| **AI Gateway** | ✅ | ✅ | ❌ | ❌ |
| **Full Observability** | ✅ | ❌ | ✅ | ✅ |
| **Caching** | ✅ | ❌ | ❌ | ❌ |
| **Custom Rate Limits** | ✅ | ❌ | ❌ | ❌ |
| **LLM Security** | ✅ | ❌ | ❌ | ❌ |
| **Session Debugging** | ✅ | ❌ | ✅ | ✅ |
| **Prompt Management** | ✅ | ❌ | ✅ | ✅ |
| **Integration** | Proxy or SDK | Proxy | SDK only | SDK only |
| **Open Source** | ✅ | ❌ | ❌ | ✅ |
See our [OpenRouter migration guide](https://www.helicone.ai/blog/migration-openrouter) for a detailed comparison and step-by-step instructions.
See our [LLM observability platforms guide](https://www.helicone.ai/blog/the-complete-guide-to-LLM-observability-platforms) for an in-depth feature breakdown.
## Start Exploring Features
Use 100+ models through one unified API with automatic fallbacks
Debug complex AI agents and multi-step workflows
Deploy prompts without code changes
Track cost and understand the unit economics of your LLM applications
***
We built Helicone for developers with users depending on them. For the 3am outages. For the surprise bills. For finding that one broken request in millions.